Appearance
让我们来构建一个浏览器引擎吧

引言
前端有一个经典的面试题:在浏览器地址栏输入URL到最终呈现出页面,中间发生了什么?
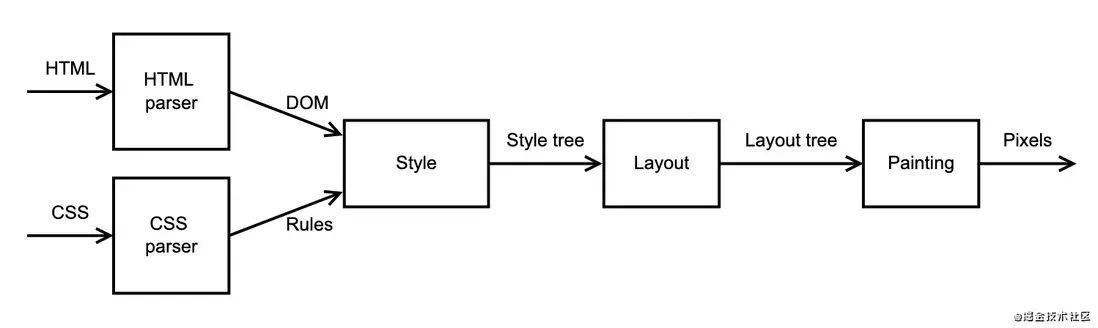
中间有一个过程是获取后台返回的HTML文本,浏览器渲染引擎将其解析成DOM树,并将HTML中的CSS解析成样式树,然后将DOM树和样式树合并成布局树,并最终由绘图程序绘制到浏览器画板上。
本文通过亲自动手实践,教你一步一步实现一个迷你版浏览器引擎,进而深入理解渲染引擎的工作原理,干货满满。
主要分成七个部分:
- 第一部分:开始
- 第二部分:HTML
- 第三部分:CSS
- 第四部分:样式
- 第五部分:盒子
- 第六部分:块布局
- 第七部分:绘制 101
原文写于2014.8.8。
原文地址:https://limpet.net/mbrubeck/2014/08/08/toy-layout-engine-1.html
以下是正文:
第一部分:开始
我正在构建一个“玩具”渲染引擎,我认为你也应该这样做。这是一系列文章中的第一篇。
完整的系列文章将描述我编写的代码,并向你展示如何编写自己的代码。但首先,让我解释一下原因。
你在造什么?
让我们谈谈术语。浏览器引擎是web浏览器的一部分,它在“底层”工作,从Internet上获取网页,并将其内容转换成可以阅读、观看、听等形式。Blink、Gecko、WebKit和Trident都是浏览器引擎。相比之下,浏览器本身的用户界面(标签、工具栏、菜单等)被称为chrome。Firefox和SeaMonkey是两个浏览器,使用不同的chrome,但使用相同的Gecko引擎。
浏览器引擎包括许多子组件:HTTP客户端、HTML解析器、CSS解析器、JavaScript引擎(本身由解析器、解释器和编译器组成)等等。那些涉及解析HTML和CSS等web格式,并将其转换成你在屏幕上看到的内容的组件,有时被称为布局引擎或渲染引擎。
为什么是一个“玩具”渲染引擎?
一个功能齐全的浏览器引擎非常复杂。Blink,Gecko,WebKit,它们每一个都有数百万行代码。更年轻、更简单的渲染引擎,如Servo和WeasyPrint,也有成千上万行。这对一个新手来说是不容易理解的!
说到非常复杂的软件:如果你参加了编译器或操作系统的课程,在某些时候你可能会创建或修改一个“玩具”编译器或内核。这是一个为学习而设计的简单模型;它可能永远不会由作者以外的任何人管理。但是
制作一个玩具系统对于了解真实的东西是如何工作的是一个有用的工具。
即使你从未构建过真实的编译器或内核,
了解它们的工作方式也可以帮助你在编写自己的程序时更好地使用它们。
因此,如果你想成为一名浏览器开发人员,或者只是想了解浏览器引擎内部发生了什么,为什么不构建一个玩具呢?就像实现“真正的”编程语言子集的玩具编译器一样,玩具渲染引擎也可以实现HTML和CSS的一小部分。它不会取代日常浏览器中的引擎,但应该能够说明呈现一个简单HTML文档所需的基本步骤。
在家试试吧。
我希望我已经说服你去试一试了。如果你已经有一些扎实的编程经验并了解一些高级HTML和CSS概念,那么学习本系列将会非常容易。然而,如果你刚刚开始学习这些东西,或者遇到你不理解的东西,请随意问问题,我会尽量让它更清楚。
在你开始之前,我想告诉你一些你可以做的选择:
关于编程语言
你可以用任何编程语言构建一个玩具式的布局引擎,真的!用一门你了解和喜爱的语言吧。如果这听起来很有趣,你也可以
以此为借口学习一门新语言。
如果你想开始为主要的浏览器引擎(如Gecko或WebKit)做贡献,你可能希望使用C++,因为C++是这些引擎中使用的主要语言,使用C++可以更容易地将你的代码与它们的代码进行比较。
我自己的玩具项目,robinson,是用Rust写的。我是Mozilla的Servo团队的一员,所以我非常喜欢Rust编程。此外,我创建这个项目的目标之一是了解更多的Servo的实现。Robinson有时会使用Servo的简化版本的数据结构和代码。
关于库和捷径
在这样的学习练习中,你必须决定是使用别人的代码,还是从头编写自己的代码。我的建议是
为你真正想要理解的部分编写你自己的代码,但是不要羞于为其他的部分使用库。
学习如何使用特定的库本身就是一项有价值的练习。
我写robinson不仅仅是为了我自己,也是为了作为这些文章和练习的示例代码。出于这样或那样的原因,我希望它尽可能地小巧和独立。到目前为止,除了Rust标准库之外,我没有使用任何外部代码。(这也避免了使用同一版本的Rust来构建多个依赖的小麻烦,而该语言仍在开发中。)不过,这个规则并不是一成不变的。例如,我以后可能会决定使用图形库,而不是编写自己的低级绘图代码。
另一种避免编写代码的方法是省略一些内容。例如,robinson还没有网络代码;它只能读取本地文件。在一个玩具程序中,如果你想跳过一些东西,你可以跳过。我将在讨论过程中指出类似的潜在捷径,这样你就可以绕过不感兴趣的步骤,直接跳到好的内容。如果你改变了主意,你可以在以后再补上空白。
第一步:DOM
准备好写代码了吗?我们将从一些小的东西开始:DOM的数据结构。让我们看看robinson的dom模块。
DOM是一个节点树。一个节点有零个或多个子节点。(它还有其他各种属性和方法,但我们现在可以忽略其中的大部分。)
javascript
struct Node {
// data common to all nodes:
children: Vec<Node>,
// data specific to each node type:
node_type: NodeType,
}有多种节点类型,但现在我们将忽略其中的大多数,并将节点定义为元素节点或文本节点。在具有继承的语言中,这些是Node的子类型。在Rust中,它们可以是枚举enum(Rust的关键字用于“tagged union”或“sum type”):
javascript
enum NodeType {
Text(String),
Element(ElementData),
}元素包括一个标记名称和任意数量的属性,它们可以存储为从名称到值的映射。Robinson不支持名称空间,所以它只将标记和属性名称存储为简单的字符串。
javascript
struct ElementData {
tag_name: String,
attributes: AttrMap,
}
type AttrMap = HashMap<String, String>;最后,一些构造函数使创建新节点变得容易:
javascript
fn text(data: String) -> Node {
Node { children: Vec::new(), node_type: NodeType::Text(data) }
}
fn elem(name: String, attrs: AttrMap, children: Vec<Node>) -> Node {
Node {
children: children,
node_type: NodeType::Element(ElementData {
tag_name: name,
attributes: attrs,
})
}
}这是它!一个成熟的DOM实现将包含更多的数据和几十个方法,但这就是我们开始所需要的。
练习
这些只是一些在家可以遵循的建议。做你感兴趣的练习,跳过不感兴趣的。
- 用你选择的语言启动一个新程序,并编写代码来表示DOM文本节点和元素树。
- 安装最新版本的Rust,然后下载并构建robinson。打开
dom.rs和扩展NodeType以包含其他类型,如注释节点。 - 编写代码来美化DOM节点树。
在下一篇文章中,我们将添加一个将HTML源代码转换为这些DOM节点树的解析器。
参考文献
有关浏览器引擎内部结构的更多详细信息,请参阅Tali Garsiel非常精彩的浏览器的工作原理及其到更多资源的链接。
例如代码,这里有一个“小型”开源web呈现引擎的简短列表。它们大多比robinson大很多倍,但仍然比Gecko或WebKit小得多。只有2000行代码的WebWhirr是唯一一个我称之为“玩具”引擎的引擎。
- CSSBox (Java)
- Cocktail (Haxe)
- gngr (Java)
- litehtml (c++)
- LURE (Lua)
- NetSurf (C)
- Servo (Rust)
- Simple San Simon (Haskell)
- WeasyPrint (Python)
- WebWhirr (C++)
你可能会发现这些有用的灵感或参考。如果你知道任何其他类似的项目,或者如果你开始自己的项目,请让我知道!
第二部分:HTML
这是构建一个玩具浏览器渲染引擎系列文章的第二篇。
本文是关于解析HTML源代码以生成DOM节点树的。解析是一个很吸引人的话题,但是我没有足够的时间或专业知识来介绍它。你可以从任何关于编译器的优秀课程或书籍中获得关于解析的详细介绍。或者通过阅读与你选择的编程语言一起工作的解析器生成器的文档来获得动手操作的开始。
HTML有自己独特的解析算法。与大多数编程语言和文件格式的解析器不同,HTML解析算法不会拒绝无效的输入。相反,它包含了特定的错误处理指令,因此web浏览器可以就如何显示每个web页面达成一致,即使是那些不符合语法规则的页面。Web浏览器必须做到这一点才能使用:因为不符合标准的HTML在Web早期就得到了支持,所以现在大部分现有Web页面都在使用它。
简单的HTML方言
我甚至没有尝试实现标准的HTML解析算法。相反,我为HTML语法的一小部分编写了一个基本解析器。我的解析器可以处理这样的简单页面:
javascript
<html>
<body>
<h1>Title</h1>
<div id="main" class="test">
<p>Hello <em>world</em>!</p>
</div>
</body>
</html>允许使用以下语法:
- 闭合的标签:
<p>…</p> - 带引号的属性:
id="main" - 文本节点:
<em>world</em>
其他所有内容都不支持,包括:
- 评论
- Doctype声明
- 转义字符(如
&)和CDATA节 - 自结束标签:
<br/>或<br>没有结束标签 - 错误处理(例如未闭合或不正确嵌套的标签)
- 名称空间和其他XHTML语法:
<html:body> - 字符编码检测
在这个项目的每个阶段,我都或多或少地编写了支持后面阶段所需的最小代码。但是如果你想学习更多的解析理论和工具,你可以在你自己的项目中更加雄心勃勃!
示例代码
接下来,让我们回顾一下我的HTML解析器,记住这只是一种方法(而且可能不是最好的方法)。它的结构松散地基于Servo的cssparser库中的tokenizer模块。它没有真正的错误处理;在大多数情况下,它只是在遇到意外的语法时中止。代码是用Rust语言写的,但我希望它对于使用类似语言(如Java、C++或C#)的人来说具有相当的可读性。它使用了第一部分中的DOM数据结构。
解析器将其输入字符串和当前位置存储在字符串中。位置是我们还没有处理的下一个字符的索引。
javascript
struct Parser {
pos: usize, // "usize" is an unsigned integer, similar to "size_t" in C
input: String,
}我们可以用它来实现一些简单的方法来窥视输入中的下一个字符:
javascript
impl Parser {
// Read the current character without consuming it.
fn next_char(&self) -> char {
self.input[self.pos..].chars().next().unwrap()
}
// Do the next characters start with the given string?
fn starts_with(&self, s: &str) -> bool {
self.input[self.pos ..].starts_with(s)
}
// Return true if all input is consumed.
fn eof(&self) -> bool {
self.pos >= self.input.len()
}
// ...
}Rust字符串存储为UTF-8字节数组。要进入下一个字符,我们不能只前进一个字节。相反,我们使用char_indices来正确处理多字节字符。(如果我们的字符串使用固定宽度的字符,我们可以只将pos加1。)
javascript
// Return the current character, and advance self.pos to the next character.
fn consume_char(&mut self) -> char {
let mut iter = self.input[self.pos..].char_indices();
let (_, cur_char) = iter.next().unwrap();
let (next_pos, _) = iter.next().unwrap_or((1, ' '));
self.pos += next_pos;
return cur_char;
}通常我们想要使用一个连续的字符串。consume_while方法使用满足给定条件的字符,并将它们作为字符串返回。这个方法的参数是一个函数,它接受一个char并返回一个bool值。
javascript
// Consume characters until `test` returns false.
fn consume_while<F>(&mut self, test: F) -> String
where F: Fn(char) -> bool {
let mut result = String::new();
while !self.eof() && test(self.next_char()) {
result.push(self.consume_char());
}
return result;
}我们可以使用它来忽略空格字符序列,或者使用字母数字字符串:
javascript
// Consume and discard zero or more whitespace characters.
fn consume_whitespace(&mut self) {
self.consume_while(CharExt::is_whitespace);
}
// Parse a tag or attribute name.
fn parse_tag_name(&mut self) -> String {
self.consume_while(|c| match c {
'a'...'z' | 'A'...'Z' | '0'...'9' => true,
_ => false
})
}现在我们已经准备好开始解析HTML了。要解析单个节点,我们查看它的第一个字符,看它是元素节点还是文本节点。在我们简化的HTML版本中,文本节点可以包含除<之外的任何字符。
javascript
// Parse a single node.
fn parse_node(&mut self) -> dom::Node {
match self.next_char() {
'<' => self.parse_element(),
_ => self.parse_text()
}
}
// Parse a text node.
fn parse_text(&mut self) -> dom::Node {
dom::text(self.consume_while(|c| c != '<'))
}一个元素更为复杂。它包括开始和结束标签,以及在它们之间任意数量的子节点:
javascript
// Parse a single element, including its open tag, contents, and closing tag.
fn parse_element(&mut self) -> dom::Node {
// Opening tag.
assert!(self.consume_char() == '<');
let tag_name = self.parse_tag_name();
let attrs = self.parse_attributes();
assert!(self.consume_char() == '>');
// Contents.
let children = self.parse_nodes();
// Closing tag.
assert!(self.consume_char() == '<');
assert!(self.consume_char() == '/');
assert!(self.parse_tag_name() == tag_name);
assert!(self.consume_char() == '>');
return dom::elem(tag_name, attrs, children);
}在我们简化的语法中,解析属性非常容易。在到达开始标记(>)的末尾之前,我们重复地查找后面跟着=的名称,然后是用引号括起来的字符串。
javascript
// Parse a single name="value" pair.
fn parse_attr(&mut self) -> (String, String) {
let name = self.parse_tag_name();
assert!(self.consume_char() == '=');
let value = self.parse_attr_value();
return (name, value);
}
// Parse a quoted value.
fn parse_attr_value(&mut self) -> String {
let open_quote = self.consume_char();
assert!(open_quote == '"' || open_quote == '\'');
let value = self.consume_while(|c| c != open_quote);
assert!(self.consume_char() == open_quote);
return value;
}
// Parse a list of name="value" pairs, separated by whitespace.
fn parse_attributes(&mut self) -> dom::AttrMap {
let mut attributes = HashMap::new();
loop {
self.consume_whitespace();
if self.next_char() == '>' {
break;
}
let (name, value) = self.parse_attr();
attributes.insert(name, value);
}
return attributes;
}为了解析子节点,我们在循环中递归地调用parse_node,直到到达结束标记。这个函数返回一个Vec,这是Rust对可增长数组的名称。
javascript
// Parse a sequence of sibling nodes.
fn parse_nodes(&mut self) -> Vec<dom::Node> {
let mut nodes = Vec::new();
loop {
self.consume_whitespace();
if self.eof() || self.starts_with("</") {
break;
}
nodes.push(self.parse_node());
}
return nodes;
}最后,我们可以把所有这些放在一起,将整个HTML文档解析成DOM树。如果文档没有显式包含根节点,则该函数将为文档创建根节点;这与真正的HTML解析器的功能类似。
javascript
// Parse an HTML document and return the root element.
pub fn parse(source: String) -> dom::Node {
let mut nodes = Parser { pos: 0, input: source }.parse_nodes();
// If the document contains a root element, just return it. Otherwise, create one.
if nodes.len() == 1 {
nodes.swap_remove(0)
} else {
dom::elem("html".to_string(), HashMap::new(), nodes)
}
}就是这样!robinson HTML解析器的全部代码。整个程序总共只有100多行代码(不包括空白行和注释)。如果你使用一个好的库或解析器生成器,你可能可以在更少的空间中构建一个类似的玩具解析器。
练习
这里有一些你可以自己尝试的替代方法。与前面一样,你可以选择其中的一个或多个,并忽略其他。
- 构建一个以HTML子集作为输入并生成DOM节点树的解析器(“手动”或使用库或解析器生成器)。
- 修改robinson的HTML解析器,添加一些缺失的特性,比如注释。或者用更好的解析器替换它,可能使用库或生成器构建。
- 创建一个无效的HTML文件,导致你的(或我的)解析器失败。修改解析器以从错误中恢复,并为测试文件生成DOM树。
捷径
如果想完全跳过解析,可以通过编程方式构建DOM树,向程序中添加类似这样的代码(伪代码,调整它以匹配第1部分中编写的DOM代码):
javascript
// <html><body>Hello, world!</body></html>
let root = element("html");
let body = element("body");
root.children.push(body);
body.children.push(text("Hello, world!"));或者你可以找到一个现有的HTML解析器并将其合并到你的程序中。
本系列的下一篇文章将讨论CSS数据结构和解析。
第三部分:CSS
本文是构建玩具浏览器呈现引擎系列文章中的第三篇。
本文介绍了用于读取层叠样式表(CSS)的代码。像往常一样,我不会试图涵盖该规范中的所有内容。相反,我尝试实现足以说明一些概念并为后期渲染管道生成输入的内容。
剖析样式表
下面是一个CSS源代码示例:
javascript
h1, h2, h3 { margin: auto; color: #cc0000; }
div.note { margin-bottom: 20px; padding: 10px; }
#answer { display: none; }接下来,我将从我的玩具浏览器引擎robinson中浏览css模块。虽然这些概念可以很容易地转换成其他编程语言,但代码还是用Rust写的。先阅读前面的文章可能会帮助您理解下面的一些代码。
CSS样式表是一系列规则。(在上面的示例样式表中,每行包含一条规则。)
javascript
struct Stylesheet {
rules: Vec<Rule>,
}一条规则包括一个或多个用逗号分隔的选择器,后跟一系列用大括号括起来的声明。
javascript
struct Rule {
selectors: Vec<Selector>,
declarations: Vec<Declaration>,
}一个选择器可以是一个简单的选择器,也可以是一个由_组合符_连接的选择器链。Robinson目前只支持简单的选择器。
注意:令人困惑的是,新的Selectors Level 3标准使用相同的术语来表示略有不同的东西。在本文中,我主要引用CSS2.1。尽管过时了,但它是一个有用的起点,因为它更小,更独立(与CSS3相比,CSS3被分成无数互相依赖和CSS2.1的规范)。
在robinson中,一个简单选择器可以包括一个标记名,一个以'#'为前缀的ID,任意数量的以'.'为前缀的类名,或以上几种情况的组合。如果标签名为空或'*',那么它是一个“通用选择器”,可以匹配任何标签。
还有许多其他类型的选择器(特别是在CSS3中),但现在这样就可以了。
javascript
enum Selector {
Simple(SimpleSelector),
}
struct SimpleSelector {
tag_name: Option<String>,
id: Option<String>,
class: Vec<String>,
}声明只是一个名称/值对,由冒号分隔并以分号结束。例如,“margin: auto;”是一个声明。
javascript
struct Declaration {
name: String,
value: Value,
}我的玩具引擎只支持CSS众多值类型中的一小部分。
javascript
enum Value {
Keyword(String),
Length(f32, Unit),
ColorValue(Color),
// insert more values here
}
enum Unit {
Px,
// insert more units here
}
struct Color {
r: u8,
g: u8,
b: u8,
a: u8,
}注意:u8是一个8位无符号整数,f32是一个32位浮点数。
不支持所有其他CSS语法,包括@-rules、注释和上面没有提到的任何选择器/值/单元。
解析
CSS有一个规则的语法,这使得它比它古怪的表亲HTML更容易正确解析。当符合标准的CSS解析器遇到解析错误时,它会丢弃样式表中无法识别的部分,但仍然处理其余部分。这是很有用的,因为它允许样式表包含新的语法,但在旧的浏览器中仍然产生定义良好的输出。
Robinson使用了一个非常简单(完全不符合标准)的解析器,构建的方式与第2部分中的HTML解析器相同。我将粘贴一些代码片段,而不是一行一行地重复整个过程。例如,下面是解析单个选择器的代码:
javascript
// Parse one simple selector, e.g.: `type#id.class1.class2.class3`
fn parse_simple_selector(&mut self) -> SimpleSelector {
let mut selector = SimpleSelector { tag_name: None, id: None, class: Vec::new() };
while !self.eof() {
match self.next_char() {
'#' => {
self.consume_char();
selector.id = Some(self.parse_identifier());
}
'.' => {
self.consume_char();
selector.class.push(self.parse_identifier());
}
'*' => {
// universal selector
self.consume_char();
}
c if valid_identifier_char(c) => {
selector.tag_name = Some(self.parse_identifier());
}
_ => break
}
}
return selector;
}注意没有错误检查。一些格式不正确的输入,如###或*foo*将成功解析并产生奇怪的结果。真正的CSS解析器会丢弃这些无效的选择器。
优先级
优先级是渲染引擎在冲突中决定哪一种样式覆盖另一种样式的方法之一。如果一个样式表包含两个匹配元素的规则,具有较高优先级的匹配选择器的规则可以覆盖较低优先级的选择器中的值。
选择器的优先级基于它的组件。ID选择器比类选择器优先级更高,类选择器比标签选择器优先级更高。在每个“层级”中,选择器越多优先级越高。
javascript
pub type Specificity = (usize, usize, usize);
impl Selector {
pub fn specificity(&self) -> Specificity {
// http://www.w3.org/TR/selectors/#specificity
let Selector::Simple(ref simple) = *self;
let a = simple.id.iter().count();
let b = simple.class.len();
let c = simple.tag_name.iter().count();
(a, b, c)
}
}(如果我们支持链选择器,我们可以通过将链各部分的优先级相加来计算链的优先级。)
每个规则的选择器都存储在排序的向量中,优先级最高的优先。这对于匹配非常重要,我将在下一篇文章中介绍。
javascript
// Parse a rule set: `<selectors> { <declarations> }`.
fn parse_rule(&mut self) -> Rule {
Rule {
selectors: self.parse_selectors(),
declarations: self.parse_declarations()
}
}
// Parse a comma-separated list of selectors.
fn parse_selectors(&mut self) -> Vec<Selector> {
let mut selectors = Vec::new();
loop {
selectors.push(Selector::Simple(self.parse_simple_selector()));
self.consume_whitespace();
match self.next_char() {
',' => { self.consume_char(); self.consume_whitespace(); }
'{' => break, // start of declarations
c => panic!("Unexpected character {} in selector list", c)
}
}
// Return selectors with highest specificity first, for use in matching.
selectors.sort_by(|a,b| b.specificity().cmp(&a.specificity()));
return selectors;
}CSS解析器的其余部分相当简单。你可以在GitHub上阅读全文。如果您在第2部分中还没有这样做,那么现在是尝试解析器生成器的绝佳时机。我的手卷解析器完成了简单示例文件的工作,但它有很多漏洞,如果您违反了它的假设,它将严重失败。有一天,我可能会用rust-peg或类似的东西来取代它。
练习
和以前一样,你应该决定你想做哪些练习,并跳过其余的:
- 实现您自己的简化CSS解析器和优先级计算。
- 扩展robinson的CSS解析器,以支持更多的值,或一个或多个选择器组合符。
- 扩展CSS解析器,丢弃任何包含解析错误的声明,并遵循错误处理规则,在声明结束后继续解析。
- 让HTML解析器将任何
<style>节点的内容传递给CSS解析器,并返回一个文档对象,该对象除了DOM树之外还包含一个样式表列表。
捷径
就像在第2部分中一样,您可以通过直接将CSS数据结构硬编码到您的程序中来跳过解析,或者通过使用已经有解析器的JSON等替代格式来编写它们。
未完待续
下一篇文章将介绍style模块。在这里,所有的一切都开始结合在一起,选择器匹配以将CSS样式应用到DOM节点。
这个系列的进度可能很快就会慢下来,因为这个月晚些时候我会很忙,我甚至还没有为即将发表的一些文章编写代码。我会让他们尽快赶到的!
第四部分:样式
欢迎回到我关于构建自己的玩具浏览器引擎的系列文章。
本文将介绍CSS标准所称的为属性值赋值,也就是我所说的样式模块。此模块将DOM节点和CSS规则作为输入,并将它们匹配起来,以确定任何给定节点的每个CSS属性的值。
这部分不包含很多代码,因为我没有实现真正复杂的部分。然而,我认为剩下的部分仍然很有趣,我还将解释一些缺失的部分如何实现。
样式树
robinson的样式模块的输出是我称之为样式树的东西。这棵树中的每个节点都包含一个指向DOM节点的指针,以及它的CSS属性值:
javascript
// Map from CSS property names to values.
type PropertyMap = HashMap<String, Value>;
// A node with associated style data.
struct StyledNode<'a> {
node: &'a Node, // pointer to a DOM node
specified_values: PropertyMap,
children: Vec<StyledNode<'a>>,
}这些
'a是什么?这些都是生存期,这是Rust如何保证指针是内存安全的,而不需要进行垃圾回收的部分原因。如果你不是在Rust的环境中工作,你可以忽略它们;它们对代码的意义并不重要。
我们可以向dom::Node结构添加新的字段,而不是创建一个新的树,但我想让样式代码远离早期的“教训”。这也让我有机会讨论大多数渲染引擎中的平行树。
浏览器引擎模块通常以一个树作为输入,然后产生一个不同但相关的树作为输出。例如,Gecko的布局代码获取一个DOM树并生成一个框架树,然后使用它来构建一个视图树。Blink和WebKit将DOM树转换为渲染树。所有这些引擎的后期阶段会产生更多的树,包括层树和部件树。
在我们完成了更多的阶段后,我们的玩具浏览器引擎的管道将看起来像这样:
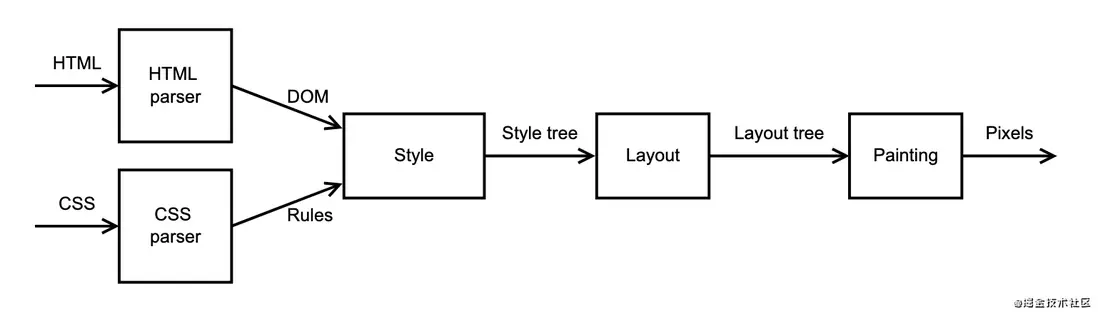
在我的实现中,DOM树中的每个节点在样式树中只有一个节点。但在更复杂的管道阶段,几个输入节点可能会分解为一个输出节点。或者一个输入节点可能扩展为几个输出节点,或者完全跳过。例如,样式树可以排除显示属性设置为'none'的元素。(相反,我将在布局阶段删除这些内容,因为这样我的代码会变得更简单一些。)
选择器匹配
构建样式树的第一步是选择器匹配。这将非常容易,因为我的CSS解析器只支持简单的选择器。您可以通过查看元素本身来判断一个简单的选择器是否匹配一个元素。匹配复合选择器需要遍历DOM树以查看元素的兄弟元素、父元素等。
javascript
fn matches(elem: &ElementData, selector: &Selector) -> bool {
match *selector {
Simple(ref simple_selector) => matches_simple_selector(elem, simple_selector)
}
}为了有所帮助,我们将向DOM元素类型添加一些方便的ID和类访问器。class属性可以包含多个用空格分隔的类名,我们在散列表中返回这些类名。
javascript
impl ElementData {
pub fn id(&self) -> Option<&String> {
self.attributes.get("id")
}
pub fn classes(&self) -> HashSet<&str> {
match self.attributes.get("class") {
Some(classlist) => classlist.split(' ').collect(),
None => HashSet::new()
}
}
}要测试一个简单的选择器是否匹配一个元素,只需查看每个选择器组件,如果元素没有匹配的类、ID或标记名,则返回false。
javascript
fn matches_simple_selector(elem: &ElementData, selector: &SimpleSelector) -> bool {
// Check type selector
if selector.tag_name.iter().any(|name| elem.tag_name != *name) {
return false;
}
// Check ID selector
if selector.id.iter().any(|id| elem.id() != Some(id)) {
return false;
}
// Check class selectors
let elem_classes = elem.classes();
if selector.class.iter().any(|class| !elem_classes.contains(&**class)) {
return false;
}
// We didn't find any non-matching selector components.
return true;
}注意:这个函数使用any方法,如果迭代器包含一个通过所提供的测试的元素,则该方法返回true。这与Python中的any函数(或Haskell)或JavaScript中的some方法相同。
构建样式树
接下来,我们需要遍历DOM树。对于树中的每个元素,我们将在样式表中搜索匹配规则。
当比较两个匹配相同元素的规则时,我们需要使用来自每个匹配的最高优先级选择器。因为我们的CSS解析器存储了从优先级从高低的选择器,所以只要找到了匹配的选择器,我们就可以停止,并返回它的优先级以及指向规则的指针。
javascript
type MatchedRule<'a> = (Specificity, &'a Rule);
// If `rule` matches `elem`, return a `MatchedRule`. Otherwise return `None`.
fn match_rule<'a>(elem: &ElementData, rule: &'a Rule) -> Option<MatchedRule<'a>> {
// Find the first (highest-specificity) matching selector.
rule.selectors.iter()
.find(|selector| matches(elem, *selector))
.map(|selector| (selector.specificity(), rule))
}为了找到与一个元素匹配的所有规则,我们称之为filter_map,它对样式表进行线性扫描,检查每个规则并排除不匹配的规则。真正的浏览器引擎会根据标签名称、id、类等将规则存储在多个散列表中,从而加快速度。
javascript
// Find all CSS rules that match the given element.
fn matching_rules<'a>(elem: &ElementData, stylesheet: &'a Stylesheet) -> Vec<MatchedRule<'a>> {
stylesheet.rules.iter().filter_map(|rule| match_rule(elem, rule)).collect()
}一旦有了匹配规则,就可以为元素找到指定的值。我们将每个规则的属性值插入到HashMap中。我们根据优先级对匹配进行排序,因此在较不特定的规则之后处理更特定的规则,并可以覆盖它们在HashMap中的值。
javascript
// Apply styles to a single element, returning the specified values.
fn specified_values(elem: &ElementData, stylesheet: &Stylesheet) -> PropertyMap {
let mut values = HashMap::new();
let mut rules = matching_rules(elem, stylesheet);
// Go through the rules from lowest to highest specificity.
rules.sort_by(|&(a, _), &(b, _)| a.cmp(&b));
for (_, rule) in rules {
for declaration in &rule.declarations {
values.insert(declaration.name.clone(), declaration.value.clone());
}
}
return values;
}现在,我们已经拥有遍历DOM树和构建样式树所需的一切。注意,选择器匹配只对元素有效,因此文本节点的指定值只是一个空映射。
javascript
// Apply a stylesheet to an entire DOM tree, returning a StyledNode tree.
pub fn style_tree<'a>(root: &'a Node, stylesheet: &'a Stylesheet) -> StyledNode<'a> {
StyledNode {
node: root,
specified_values: match root.node_type {
Element(ref elem) => specified_values(elem, stylesheet),
Text(_) => HashMap::new()
},
children: root.children.iter().map(|child| style_tree(child, stylesheet)).collect(),
}
}这就是robinson构建样式树的全部代码。接下来我将讨论一些明显的遗漏。
级联
由web页面的作者提供的样式表称为_作者样式表_。除此之外,浏览器还通过_用户代理样式表_提供默认样式。它们可能允许用户通过_用户样式表_(如Gecko的userContent.css)添加自定义样式。
级联定义这三个“起源”中哪个优先于另一个。级联有6个级别:一个用于每个起源的“正常”声明,另一个用于每个起源的!important声明。
Robinson的风格代码没有实现级联;它只需要一个样式表。缺少默认样式表意味着HTML元素将不具有任何您可能期望的默认样式。例如,<head>元素的内容不会被隐藏,除非你显式地把这个规则添加到你的样式表中:
javascript
head { display: none; }实现级联应该相当简单:只需跟踪每个规则的起源,并根据起源和重要性以及特殊性对声明进行排序。一个简化的、两级的级联应该足以支持最常见的情况:普通用户代理样式和普通作者样式。
计算的值
除了上面提到的“指定值”之外,CSS还定义了初始值、计算值、使用值和实际值。
_初始值_是没有在级联中指定的属性的默认值。_计算值_基于指定值,但可能应用一些特定于属性的规范化规则。
根据CSS规范中的定义,正确实现这些需要为每个属性单独编写代码。对于一个真实的浏览器引擎来说,这项工作是必要的,但我希望在这个玩具项目中避免它。在后面的阶段,当指定的值缺失时,使用这些值的代码将(某种程度上)通过使用默认值模拟初始值。
_使用值_和_实际值_是在布局期间和之后计算的,我将在以后的文章中介绍。
继承
如果文本节点不能匹配选择器,它们如何获得颜色、字体和其他样式?答案是继承。
当属性被继承时,任何没有级联值的节点都将接收该属性的父节点值。有些属性,如'color',是默认继承的;其他仅当级联指定特殊值“inherit”时使用。
我的代码不支持继承。要实现它,可以将父类的样式数据传递到specified_values函数,并使用硬编码的查找表来决定应该继承哪些属性。
样式属性
任何HTML元素都可以包含一个包含CSS声明列表的样式属性。没有选择器,因为这些声明自动只应用于元素本身。
javascript
<span style="color: red; background: yellow;">如果您想要支持style属性,请使用specified_values函数检查该属性。如果存在该属性,则将其从CSS解析器传递给parse_declarations。在普通的作者声明之后应用结果声明,因为属性比任何CSS选择器都更特定。
练习
除了编写自己的选择器匹配和值赋值代码之外,你还可以在自己的项目或robinson的分支中实现上面讨论的一个或多个缺失的部分:
- 级联
- 初始值和/或计算值
- 继承
- 样式属性
另外,如果您从第3部分扩展了CSS解析器以包含复合选择器,那么现在可以实现对这些复合选择器的匹配。
未完待续
第5部分将介绍布局模块。我还没有完成代码,所以在我开始写这篇文章之前还会有另一个延迟。我计划将布局分成至少两篇文章(一篇是块布局,一篇可能是内联布局)。
与此同时,我希望看到您根据这些文章或练习创建的任何东西。如果你的代码在某个地方,请在下面添加一个链接!到目前为止,我已经看到了Martin Tomasi的Java实现和Pohl longsin的Swift版本。
第五部分:盒子
这是关于编写一个简单的HTML渲染引擎的系列文章中的第5篇。
本文将开始布局模块,该模块获取样式树并将其转换为二维空间中的一堆矩形。这是一个很大的模块,所以我将把它分成几篇文章。另外,在我为后面的部分编写代码时,我在本文中分享的一些代码可能需要更改。
布局模块的输入是第4部分中的样式树,它的输出是另一棵树,即布局树。这使我们的迷你渲染管道更进一步:
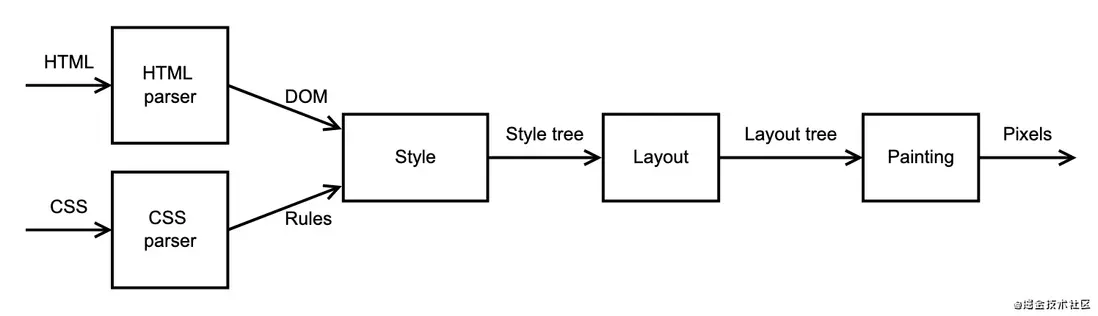
我将从基本的HTML/CSS布局模型开始讨论。如果您曾经学习过如何开发web页面,那么您可能已经熟悉了这一点,但是从实现者的角度来看,它可能有点不同。
盒模型
布局就是方框。方框是网页的一个矩形部分。它具有页面上的宽度、高度和位置。这个矩形称为内容区域,因为它是框的内容绘制的地方。内容可以是文本、图像、视频或其他框。
框还可以在其内容区域周围有内边距、边框和边距。CSS规范中有一个图表显示所有这些层是如何组合在一起的。
Robinson将盒子的内容区域和周围区域存储在下面的结构中。[Rust注:f32是32位浮点型。]
javascript
// CSS box model. All sizes are in px.
struct Dimensions {
// Position of the content area relative to the document origin:
content: Rect,
// Surrounding edges:
padding: EdgeSizes,
border: EdgeSizes,
margin: EdgeSizes,
}
struct Rect {
x: f32,
y: f32,
width: f32,
height: f32,
}
struct EdgeSizes {
left: f32,
right: f32,
top: f32,
bottom: f32,
}块和内联布局
注意:这部分包含的图表如果没有相关的视觉样式,就没有意义。如果您是在一个提要阅读器中阅读这篇文章,尝试在一个常规的浏览器选项卡中打开原始页面。我还为使用屏幕阅读器或其他辅助技术的读者提供了文本描述。
CSS display属性决定一个元素生成哪种类型的框。CSS定义了几种框类型,每种都有自己的布局规则。我只讲其中的两种:块和内联。
我将使用这一点伪html来说明区别:
javascript
<container>
<a></a>
<b></b>
<c></c>
<d></d>
</container>块级框从上到下垂直地放置在容器中。
javascript
a, b, c, d { display: block; }
行内框从左到右水平地放置在容器中。如果它们到达了容器的右边缘,它们将环绕并继续在下面的新行。
javascript
a, b, c, d { display: inline; }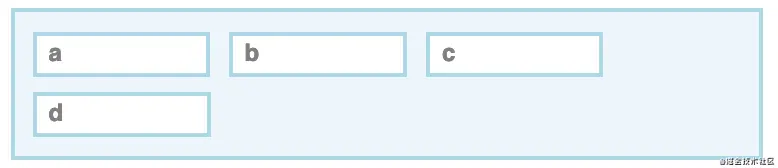
每个框必须只包含块级子元素或行内子元素。当DOM元素包含块级子元素和内联子元素时,布局引擎会插入匿名框来分隔这两种类型。(这些框是“匿名的”,因为它们与DOM树中的节点没有关联。)
在这个例子中,内联框b和c被一个匿名块框包围,粉红色显示:
javascript
a { display: block; }
b, c { display: inline; }
d { display: block; }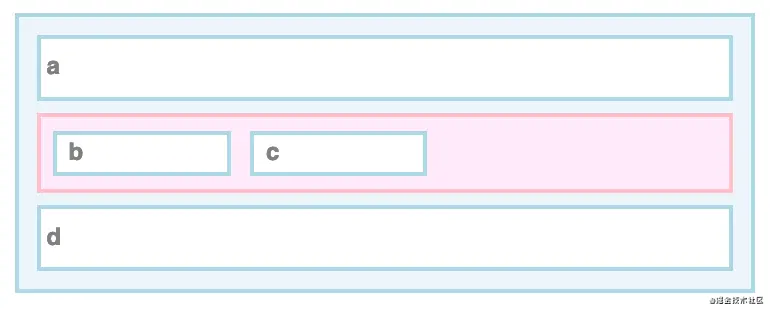
注意,内容默认垂直增长。也就是说,向容器中添加子元素通常会使容器更高,而不是更宽。另一种说法是,默认情况下,块或行的宽度取决于其容器的宽度,而容器的高度取决于其子容器的高度。
如果你覆盖了属性的默认值,比如宽度和高度,这将变得更加复杂,如果你想要支持像垂直书写这样的特性,这将变得更加复杂。
布局树
布局树是一个框的集合。一个盒子有尺寸,它可能包含子盒子。
javascript
struct LayoutBox<'a> {
dimensions: Dimensions,
box_type: BoxType<'a>,
children: Vec<LayoutBox<'a>>,
}框可以是块节点、内联节点或匿名块框。(当我实现文本布局时,这需要改变,因为行换行会导致一个内联节点被分割成多个框。但现在就可以了。)
javascript
enum BoxType<'a> {
BlockNode(&'a StyledNode<'a>),
InlineNode(&'a StyledNode<'a>),
AnonymousBlock,
}要构建布局树,我们需要查看每个DOM节点的display属性。我向style模块添加了一些代码,以获取节点的显示值。如果没有指定值,则返回初始值'inline'。
javascript
enum Display {
Inline,
Block,
None,
}
impl StyledNode {
// Return the specified value of a property if it exists, otherwise `None`.
fn value(&self, name: &str) -> Option<Value> {
self.specified_values.get(name).map(|v| v.clone())
}
// The value of the `display` property (defaults to inline).
fn display(&self) -> Display {
match self.value("display") {
Some(Keyword(s)) => match &*s {
"block" => Display::Block,
"none" => Display::None,
_ => Display::Inline
},
_ => Display::Inline
}
}
}现在我们可以遍历样式树,为每个节点构建一个LayoutBox,然后为节点的子节点插入框。如果一个节点的display属性被设置为'none',那么它就不包含在布局树中。
javascript
// Build the tree of LayoutBoxes, but don't perform any layout calculations yet.
fn build_layout_tree<'a>(style_node: &'a StyledNode<'a>) -> LayoutBox<'a> {
// Create the root box.
let mut root = LayoutBox::new(match style_node.display() {
Block => BlockNode(style_node),
Inline => InlineNode(style_node),
DisplayNone => panic!("Root node has display: none.")
});
// Create the descendant boxes.
for child in &style_node.children {
match child.display() {
Block => root.children.push(build_layout_tree(child)),
Inline => root.get_inline_container().children.push(build_layout_tree(child)),
DisplayNone => {} // Skip nodes with `display: none;`
}
}
return root;
}
impl LayoutBox {
// Constructor function
fn new(box_type: BoxType) -> LayoutBox {
LayoutBox {
box_type: box_type,
dimensions: Default::default(), // initially set all fields to 0.0
children: Vec::new(),
}
}
// ...
}如果块节点包含内联子节点,则创建一个匿名块框来包含它。如果一行中有几个内联子元素,则将它们都放在同一个匿名容器中。
javascript
// Where a new inline child should go.
fn get_inline_container(&mut self) -> &mut LayoutBox {
match self.box_type {
InlineNode(_) | AnonymousBlock => self,
BlockNode(_) => {
// If we've just generated an anonymous block box, keep using it.
// Otherwise, create a new one.
match self.children.last() {
Some(&LayoutBox { box_type: AnonymousBlock,..}) => {}
_ => self.children.push(LayoutBox::new(AnonymousBlock))
}
self.children.last_mut().unwrap()
}
}
}这是有意从标准CSS框生成算法的多种方式简化的。例如,它不处理内联框包含块级子框的情况。此外,如果块级节点只有内联子节点,则会生成一个不必要的匿名框。
未完待续
哇,比我想象的要长。我想我就讲到这里,但是不要担心:第6部分很快就会到来,它将讨论块级布局。
一旦块布局完成,我们就可以跳转到管道的下一个阶段:绘制!我想我可能会这么做,因为这样我们最终可以看到渲染引擎的输出是漂亮的图片而不是数字。
然而,这些图片将只是一堆彩色的矩形,除非我们通过实现内联布局和文本布局来完成布局模块。如果我在开始绘画之前没有实现这些,我希望之后再回到它们上来。
第六部分:块布局
欢迎回到我关于构建一个玩具HTML渲染引擎的系列文章,这是系列文章的第6篇。
本文将继续我们在第5部分中开始的布局模块。这一次,我们将添加布局块框的功能。这些框是垂直堆叠的,比如标题和段落。
为了简单起见,这段代码只实现了正常流:没有浮动,没有绝对定位,也没有固定定位。
遍历布局树
该代码的入口点是layout函数,它接受一个LayoutBox并计算其尺寸。我们将把这个函数分为三种情况,目前只实现其中一种:
javascript
impl LayoutBox {
// Lay out a box and its descendants.
fn layout(&mut self, containing_block: Dimensions) {
match self.box_type {
BlockNode(_) => self.layout_block(containing_block),
InlineNode(_) => {} // TODO
AnonymousBlock => {} // TODO
}
}
// ...
}一个块的布局取决于它所包含块的尺寸。对于正常流中的块框,这只是框的父。对于根元素,它是浏览器窗口(或“视口”)的大小。
您可能还记得在前一篇文章中,一个块的宽度取决于它的父块,而它的高度取决于它的子块。这意味着我们的代码在计算宽度时需要自顶向下遍历树,因此它可以在父类的宽度已知之后布局子类,并自底向上遍历以计算高度,因此父类的高度在其子类的高度之后计算。
javascript
fn layout_block(&mut self, containing_block: Dimensions) {
// Child width can depend on parent width, so we need to calculate
// this box's width before laying out its children.
self.calculate_block_width(containing_block);
// Determine where the box is located within its container.
self.calculate_block_position(containing_block);
// Recursively lay out the children of this box.
self.layout_block_children();
// Parent height can depend on child height, so `calculate_height`
// must be called *after* the children are laid out.
self.calculate_block_height();
}该函数对布局树执行一次遍历,向下时进行宽度计算,向上时进行高度计算。一个真正的布局引擎可能会执行几次树遍历,一些是自顶向下,一些是自底向上。
计算宽度
宽度计算是块布局函数的第一步,也是最复杂的一步。我要一步一步来。首先,我们需要CSS宽度属性的值和所有左右边的大小:
javascript
fn calculate_block_width(&mut self, containing_block: Dimensions) {
let style = self.get_style_node();
// `width` has initial value `auto`.
let auto = Keyword("auto".to_string());
let mut width = style.value("width").unwrap_or(auto.clone());
// margin, border, and padding have initial value 0.
let zero = Length(0.0, Px);
let mut margin_left = style.lookup("margin-left", "margin", &zero);
let mut margin_right = style.lookup("margin-right", "margin", &zero);
let border_left = style.lookup("border-left-width", "border-width", &zero);
let border_right = style.lookup("border-right-width", "border-width", &zero);
let padding_left = style.lookup("padding-left", "padding", &zero);
let padding_right = style.lookup("padding-right", "padding", &zero);
// ...
}这使用了一个名为lookup的助手函数,它只是按顺序尝试一系列值。如果第一个属性没有设置,它将尝试第二个属性。如果没有设置,它将返回给定的默认值。这提供了一个不完整(但简单)的简写属性和初始值实现。
注意:这类似于JavaScript或Ruby中的以下代码:
javascript
margin_left = style["margin-left"] || style["margin"] || zero;因为子对象不能改变父对象的宽度,所以它需要确保自己的宽度与父对象的宽度相符。CSS规范将其表达为一组约束和解决它们的算法。下面的代码实现了该算法。
首先,我们将边距、内边距、边框和内容宽度相加。to_px帮助器方法将长度转换为它们的数值。如果一个属性被设置为'auto',它会返回0,因此它不会影响和。
javascript
let total = [&margin_left, &margin_right, &border_left, &border_right,
&padding_left, &padding_right, &width].iter().map(|v| v.to_px()).sum();这是盒子所需要的最小水平空间。如果它不等于容器的宽度,我们需要调整一些东西使它相等。
如果宽度或边距设置为“auto”,它们可以扩展或收缩以适应可用的空间。按照说明书,我们首先检查盒子是否太大。如果是这样,我们将任何可扩展边距设置为零。
javascript
// If width is not auto and the total is wider than the container, treat auto margins as 0.
if width != auto && total > containing_block.content.width {
if margin_left == auto {
margin_left = Length(0.0, Px);
}
if margin_right == auto {
margin_right = Length(0.0, Px);
}
}如果盒子对容器来说太大,就会溢出容器。如果太小,它就会下泄,留下额外的空间。我们将计算下溢量,即容器内剩余空间的大小。(如果这个数字是负数,它实际上是一个溢出。)
javascript
let underflow = containing_block.content.width - total;我们现在遵循规范的算法,通过调整可扩展的尺寸来消除任何溢出或下溢。如果没有“自动”尺寸,我们调整右边的边距。(是的,这意味着在溢出的情况下,边界可能是负的!)
javascript
match (width == auto, margin_left == auto, margin_right == auto) {
// If the values are overconstrained, calculate margin_right.
(false, false, false) => {
margin_right = Length(margin_right.to_px() + underflow, Px);
}
// If exactly one size is auto, its used value follows from the equality.
(false, false, true) => { margin_right = Length(underflow, Px); }
(false, true, false) => { margin_left = Length(underflow, Px); }
// If width is set to auto, any other auto values become 0.
(true, _, _) => {
if margin_left == auto { margin_left = Length(0.0, Px); }
if margin_right == auto { margin_right = Length(0.0, Px); }
if underflow >= 0.0 {
// Expand width to fill the underflow.
width = Length(underflow, Px);
} else {
// Width can't be negative. Adjust the right margin instead.
width = Length(0.0, Px);
margin_right = Length(margin_right.to_px() + underflow, Px);
}
}
// If margin-left and margin-right are both auto, their used values are equal.
(false, true, true) => {
margin_left = Length(underflow / 2.0, Px);
margin_right = Length(underflow / 2.0, Px);
}
}此时,约束已经满足,任何'auto'值都已经转换为长度。结果是水平框尺寸的使用值,我们将把它存储在布局树中。你可以在layout.rs中看到最终的代码。
定位
下一步比较简单。这个函数查找剩余的边距/内边距/边框样式,并使用这些样式和包含的块尺寸来确定这个块在页面上的位置。
javascript
fn calculate_block_position(&mut self, containing_block: Dimensions) {
let style = self.get_style_node();
let d = &mut self.dimensions;
// margin, border, and padding have initial value 0.
let zero = Length(0.0, Px);
// If margin-top or margin-bottom is `auto`, the used value is zero.
d.margin.top = style.lookup("margin-top", "margin", &zero).to_px();
d.margin.bottom = style.lookup("margin-bottom", "margin", &zero).to_px();
d.border.top = style.lookup("border-top-width", "border-width", &zero).to_px();
d.border.bottom = style.lookup("border-bottom-width", "border-width", &zero).to_px();
d.padding.top = style.lookup("padding-top", "padding", &zero).to_px();
d.padding.bottom = style.lookup("padding-bottom", "padding", &zero).to_px();
d.content.x = containing_block.content.x +
d.margin.left + d.border.left + d.padding.left;
// Position the box below all the previous boxes in the container.
d.content.y = containing_block.content.height + containing_block.content.y +
d.margin.top + d.border.top + d.padding.top;
}仔细看看最后一条语句,它设置了y的位置。这就是为什么块布局具有独特的垂直堆叠行为。为了实现这一点,我们需要确保父节点的内容。高度在布局每个子元素后更新。
子元素
下面是递归布局框内容的代码。当它循环遍历子框时,它会跟踪总内容高度。定位代码(上面)使用这个函数来查找下一个子元素的垂直位置。
javascript
fn layout_block_children(&mut self) {
let d = &mut self.dimensions;
for child in &mut self.children {
child.layout(*d);
// Track the height so each child is laid out below the previous content.
d.content.height = d.content.height + child.dimensions.margin_box().height;
}
}每个子节点占用的总垂直空间是其边距框的高度,我们是这样计算的:
javascript
impl Dimensions {
// The area covered by the content area plus its padding.
fn padding_box(self) -> Rect {
self.content.expanded_by(self.padding)
}
// The area covered by the content area plus padding and borders.
fn border_box(self) -> Rect {
self.padding_box().expanded_by(self.border)
}
// The area covered by the content area plus padding, borders, and margin.
fn margin_box(self) -> Rect {
self.border_box().expanded_by(self.margin)
}
}
impl Rect {
fn expanded_by(self, edge: EdgeSizes) -> Rect {
Rect {
x: self.x - edge.left,
y: self.y - edge.top,
width: self.width + edge.left + edge.right,
height: self.height + edge.top + edge.bottom,
}
}
}为简单起见,这里没有实现边距折叠。一个真正的布局引擎会允许一个框的底部边缘与下一个框的顶部边缘重叠,而不是每个框都完全放在前一个框的下面。
“高度”属性
默认情况下,框的高度等于其内容的高度。但如果'height'属性被显式设置为长度,我们将使用它来代替:
javascript
fn calculate_block_height(&mut self) {
// If the height is set to an explicit length, use that exact length.
// Otherwise, just keep the value set by `layout_block_children`.
if let Some(Length(h, Px)) = self.get_style_node().value("height") {
self.dimensions.content.height = h;
}
}这就是块布局算法。现在你可以在一个HTML文档上调用layout(),它会生成一堆矩形,包括宽度、高度、边距等。很酷,对吧?
练习
对于雄心勃勃的实现者,一些额外的想法:
- 崩溃的垂直边缘。
- 相对定位。
- 并行化布局过程,并测量对性能的影响。
如果您尝试并行化项目,您可能想要将宽度计算和高度计算分离为两个不同的通道。通过为每个子任务生成一个单独的任务,从上至下遍历宽度很容易并行化。高度的计算要稍微复杂一些,因为您需要返回并在每个子元素被布局之后调整它们的y位置。
未完待续
感谢所有跟随我走到这一步的人!
随着我深入到布局和渲染的陌生领域,这些文章的编写时间越来越长。在我试验字体和图形代码的下一部分之前,会有一段较长的时间中断,但我会尽快恢复这个系列。
更新:第7部分现在准备好了。
第七部分:绘制 101
欢迎回到我的关于构建一个简单HTML渲染引擎的系列,这是第7篇,也是最后一篇。
在这篇文章中,我将添加非常基本的绘画代码。这段代码从布局模块中获取框树,并将它们转换为像素数组。这个过程也称为“栅格化”。
浏览器通常在Skia、Cairo、Direct2D等图形api和库的帮助下实现光栅化。这些api提供了绘制多边形、直线、曲线、渐变和文本的函数。现在,我将编写我自己的光栅化程序,它只能绘制一种东西:矩形。
最后我想实现文本渲染。在这一点上,我可能会抛弃这个玩具绘画代码,转而使用“真正的”2D图形库。但就目前而言,矩形足以将我的块布局算法的输出转换为图片。
迎头赶上
从上一篇文章开始,我对以前文章中的代码做了一些小的修改。这包括一些小的重构,以及一些更新,以保持代码与最新的Rust夜间构建兼容。这些更改对理解代码都不是至关重要的,但是如果您好奇的话,可以查看提交历史记录。
构建显示列表
在绘制之前,我们将遍历布局树并构建一个显示列表。这是一个图形操作列表,如“绘制圆圈”或“绘制文本字符串”。或者在我们的例子中,只是“画一个矩形”。
为什么要将命令放入显示列表中,而不是立即执行它们?显示列表之所以有用有几个原因。你可以通过搜索来找到被后期操作完全掩盖的物品,并将其移除,以消除浪费的油漆。在只知道某些项发生了更改的情况下,可以修改和重用显示列表。您可以使用相同的显示列表生成不同类型的输出:例如,用于在屏幕上显示的像素,或用于发送到打印机的矢量图形。
Robinson的显示列表是显示命令的向量。目前,只有一种类型的DisplayCommand,一个纯色矩形:
javascript
type DisplayList = Vec<DisplayCommand>;
enum DisplayCommand {
SolidColor(Color, Rect),
// insert more commands here
}为了构建显示列表,我们遍历布局树并为每个框生成一系列命令。首先,我们绘制框的背景,然后在背景顶部绘制边框和内容。
javascript
fn build_display_list(layout_root: &LayoutBox) -> DisplayList {
let mut list = Vec::new();
render_layout_box(&mut list, layout_root);
return list;
}
fn render_layout_box(list: &mut DisplayList, layout_box: &LayoutBox) {
render_background(list, layout_box);
render_borders(list, layout_box);
// TODO: render text
for child in &layout_box.children {
render_layout_box(list, child);
}
}默认情况下,HTML元素是按照它们出现的顺序堆叠的:如果两个元素重叠,则后面的元素画在前面的元素之上。这反映在我们的显示列表中,它将按照它们在DOM树中出现的顺序绘制元素。如果这段代码支持z-index属性,那么各个元素将能够覆盖这个堆叠顺序,我们需要相应地对显示列表进行排序。
背景很简单。它只是一个实心矩形。如果没有指定背景颜色,那么背景是透明的,我们不需要生成显示命令。
javascript
fn render_background(list: &mut DisplayList, layout_box: &LayoutBox) {
get_color(layout_box, "background").map(|color|
list.push(DisplayCommand::SolidColor(color, layout_box.dimensions.border_box())));
}
// Return the specified color for CSS property `name`, or None if no color was specified.
fn get_color(layout_box: &LayoutBox, name: &str) -> Option<Color> {
match layout_box.box_type {
BlockNode(style) | InlineNode(style) => match style.value(name) {
Some(Value::ColorValue(color)) => Some(color),
_ => None
},
AnonymousBlock => None
}
}边框是相似的,但是我们不是画一个单独的矩形,而是每条边框都画4 - 1。
javascript
fn render_borders(list: &mut DisplayList, layout_box: &LayoutBox) {
let color = match get_color(layout_box, "border-color") {
Some(color) => color,
_ => return // bail out if no border-color is specified
};
let d = &layout_box.dimensions;
let border_box = d.border_box();
// Left border
list.push(DisplayCommand::SolidColor(color, Rect {
x: border_box.x,
y: border_box.y,
width: d.border.left,
height: border_box.height,
}));
// Right border
list.push(DisplayCommand::SolidColor(color, Rect {
x: border_box.x + border_box.width - d.border.right,
y: border_box.y,
width: d.border.right,
height: border_box.height,
}));
// Top border
list.push(DisplayCommand::SolidColor(color, Rect {
x: border_box.x,
y: border_box.y,
width: border_box.width,
height: d.border.top,
}));
// Bottom border
list.push(DisplayCommand::SolidColor(color, Rect {
x: border_box.x,
y: border_box.y + border_box.height - d.border.bottom,
width: border_box.width,
height: d.border.bottom,
}));
}接下来,渲染函数将绘制盒子的每个子元素,直到整个布局树被转换成显示命令为止。
光栅化
现在我们已经构建了显示列表,我们需要通过执行每个DisplayCommand将其转换为像素。我们将把像素存储在画布中:
javascript
struct Canvas {
pixels: Vec<Color>,
width: usize,
height: usize,
}
impl Canvas {
// Create a blank canvas
fn new(width: usize, height: usize) -> Canvas {
let white = Color { r: 255, g: 255, b: 255, a: 255 };
return Canvas {
pixels: repeat(white).take(width * height).collect(),
width: width,
height: height,
}
}
// ...
}要在画布上绘制矩形,只需循环遍历它的行和列,使用helper方法确保不会超出画布的范围。
javascript
fn paint_item(&mut self, item: &DisplayCommand) {
match item {
&DisplayCommand::SolidColor(color, rect) => {
// Clip the rectangle to the canvas boundaries.
let x0 = rect.x.clamp(0.0, self.width as f32) as usize;
let y0 = rect.y.clamp(0.0, self.height as f32) as usize;
let x1 = (rect.x + rect.width).clamp(0.0, self.width as f32) as usize;
let y1 = (rect.y + rect.height).clamp(0.0, self.height as f32) as usize;
for y in (y0 .. y1) {
for x in (x0 .. x1) {
// TODO: alpha compositing with existing pixel
self.pixels[x + y * self.width] = color;
}
}
}
}
}注意,这段代码只适用于不透明的颜色。如果我们添加了透明度(通过读取不透明度属性,或在CSS解析器中添加对rgba()值的支持),那么它就需要将每个新像素与它所绘制的任何内容混合在一起。
现在我们可以把所有东西都放到paint函数中,它会构建一个显示列表,然后栅格化到画布上:
javascript
// Paint a tree of LayoutBoxes to an array of pixels.
fn paint(layout_root: &LayoutBox, bounds: Rect) -> Canvas {
let display_list = build_display_list(layout_root);
let mut canvas = Canvas::new(bounds.width as usize, bounds.height as usize);
for item in display_list {
canvas.paint_item(&item);
}
return canvas;
}最后,我们可以编写几行代码,使用Rust图像库将像素数组保存为PNG文件。 漂亮的图片
最后,我们已经到达渲染管道的末端。在不到1000行代码中,robinson现在可以解析这个HTML文件了:
javascript
<div class="a">
<div class="b">
<div class="c">
<div class="d">
<div class="e">
<div class="f">
<div class="g">
</div>
</div>
</div>
</div>
</div>
</div>
</div>和这个CSS文件:
javascript
* { display: block; padding: 12px; }
.a { background: #ff0000; }
.b { background: #ffa500; }
.c { background: #ffff00; }
.d { background: #008000; }
.e { background: #0000ff; }
.f { background: #4b0082; }
.g { background: #800080; }得到以下效果:

耶!
练习
如果你是独自在家玩,这里有一些你可能想尝试的事情:
编写一个替代的绘图函数,它接受显示列表并生成矢量输出(例如,SVG文件),而不是栅格图像。
添加对不透明度和alpha混合的支持。
编写一个函数,通过剔除完全超出画布边界的项来优化显示列表。
如果你熟悉OpenGL,可以编写一个使用GL着色器绘制矩形的硬件加速绘制函数。
尾声
现在我们已经获得了渲染管道中每个阶段的基本功能,现在是时候回去填补一些缺失的特性了——特别是内联布局和文本渲染。以后的文章还可能添加额外的阶段,如网络和脚本。
我将在本月的湾区Rust聚会上做一个简短的演讲,“让我们构建一个浏览器引擎吧!”会议将于明天(11月6日,周四)晚上7点在Mozilla的旧金山办公室举行,届时我的伺服开发伙伴们也将进行有关伺服的演讲。会谈的视频将在Air Mozilla上进行直播,录音将在稍后发布。
原文写于2014.8.8。
原文链接:https://limpet.net/mbrubeck/2014/08/08/toy-layout-engine-1.html